
Claude Code Memory로 프로젝트 컨텍스트 자동화하기 — 다음 대화에서도 기억하는 AI 만드는 법 (2026)
⚡ 한눈에 보는 핵심 요약 (TL;DR)
- ✅Memory는 Claude Code 공식 기능입니다. 저장 위치는
~/.claude/projects/<프로젝트>/memory/MEMORY.md로 고정되어 있고, CLAUDE.md와 별개로 동작합니다. - ✅CLAUDE.md는 사용자가 쓰는 영구 규칙, Memory는 Claude가 갱신하는 사실 기록입니다. 둘이 다른 도구라는 점부터 잡고 가면 헷갈릴 일이 없습니다.
- ✅user · feedback · project · reference 네 가지로 분류해 두면 다음 세션 첫 응답부터 컨텍스트가 살아납니다. 단, 이 분류 자체는 운영 패턴이라 공식 docs에는 별도 명시가 없습니다.
- ⚠️두 단계 저장이 핵심입니다. 메모리 본문은 개별 파일에, 한 줄 요약만
MEMORY.md인덱스에 — 인덱스는 200줄 넘으면 잘립니다. - ❌파일 경로·함수명·플래그는 메모리에 박지 마세요. 시간이 지나면 거짓이 됩니다. 사용 직전에 grep으로 다시 확인하는 습관이 함께 가야 합니다.
저는 한 컴퓨터 안에서 프로젝트를 6개 동시에 굴리고 있습니다. Astro 기반 기술 블로그, Cloudflare Workers API 서버, Next.js 포트폴리오, B2B SaaS 대시보드, 서버리스 크롤링 데이터 파이프라인, 그리고 사내 백오피스 시스템. 기술 스택도 다르고 배포 방식도 제각각이라, Claude Code를 새로 켤 때마다 같은 자기소개를 반복했습니다. “이건 Astro+Cloudflare Pages 프로젝트고요, 발행은 GitHub Push로 자동, 마크다운 파일은 src/content/blog에 있고요…” 하루에 그 설명을 다섯 번씩 했던 적도 있습니다.
오늘(2026-04-27) tech.dokyungja.us를 메인 도메인 서브폴더로 통합하는 301 리디렉션 작업을 했는데, 이게 한 번에 끝났습니다. 이전 세션에서 적어둔 메모리에 “이 사용자는 도메인 통합을 검토 중이고, Cloudflare Pages를 쓴다, _redirects 우선순위 함정에 한 번 당한 적 있다”는 정보가 살아 있었기 때문입니다. 이 글은 그 메모리 시스템을 직접 운영해 보면서 배운 것을 초보자용으로 정리한 글입니다.

Claude Code Memory가 정확히 뭔가요
Claude Code Memory는 Anthropic이 정식으로 제공하는 영속 컨텍스트 시스템입니다. 한 대화가 끝나도 사라지지 않고 다음 세션이 자동으로 읽어 들이는 파일 묶음이라고 생각하면 쉽습니다. 공식 문서는 code.claude.com/docs/en/memory.md에 있고, “Auto memory”라는 이름으로 부릅니다.
여기서 가장 자주 나오는 오해부터 잡고 가겠습니다.
- CLAUDE.md: 사용자가 직접 쓰는 프로젝트 영구 규칙 파일입니다. “이 레포는 pnpm 쓴다”, “테스트는 vitest 쓴다”, “한국어 주석 금지” 같은 변하지 않는 약속을 적습니다.
- Memory: Claude가 자동으로 갱신하는 사실 기록 파일들입니다. “이 사용자는 Astro 7년차다”, “지난번 마이그레이션은 Cloudflare _redirects 우선순위 때문에 한 번 깨졌다” 같은 누적 지식이 들어갑니다.
CLAUDE.md는 모두를 위한 규칙집이고, Memory는 나를 위한 다이어리에 가깝습니다. 둘 다 다음 대화에 자동 로드되지만, 역할이 완전히 다릅니다.

내 메모리 폴더는 어디에 있을까
경로 규칙은 단순합니다. 작업 디렉터리의 절대경로에서 슬래시(/)를 하이픈(-)으로 바꾼 슬러그가 폴더 이름이 됩니다. 제 경우는 이렇습니다.
~/.claude/projects/-Volumes-Samsung-X5-Blogs-dev-blog/memory/
├── MEMORY.md
├── user_role.md
├── feedback_writing_style.md
├── project_domain_migration.md
└── reference_naver_blog_api.md지금 바로 본인 폴더를 확인하려면 터미널에서 한 줄이면 됩니다.
ls ~/.claude/projects/$(pwd | sed 's|/|-|g')/memory/ 2>/dev/null || echo "아직 메모리 없음"
폴더가 비어 있다면 아직 Claude가 메모리를 저장한 적이 없다는 뜻입니다. 다음 절에서 뭘 어떻게 저장하는지 보면, 자연스럽게 채워집니다.
4가지 분류로 메모리를 정리하기 — user · feedback · project · reference
⚠️ 팩트체크
아래 4가지 분류는 Anthropic 공식 docs(code.claude.com/docs/en/memory.md)에는 명시되지 않았습니다. Claude가 자동으로 메모리를 작성할 때 시스템 가이드라인 차원에서 권장되는 운영 패턴이며, 사용자가 직접 채택해 쓸 수 있는 분류입니다. 본인이 다른 카테고리(infra.md, billing.md 등)로 나눠도 무방합니다.
제 환경에서는 4가지로 나눠 운영 중입니다. 무엇이 어디로 가야 하는지 헷갈리지 않으려면 이 그림이 가장 빠릅니다.
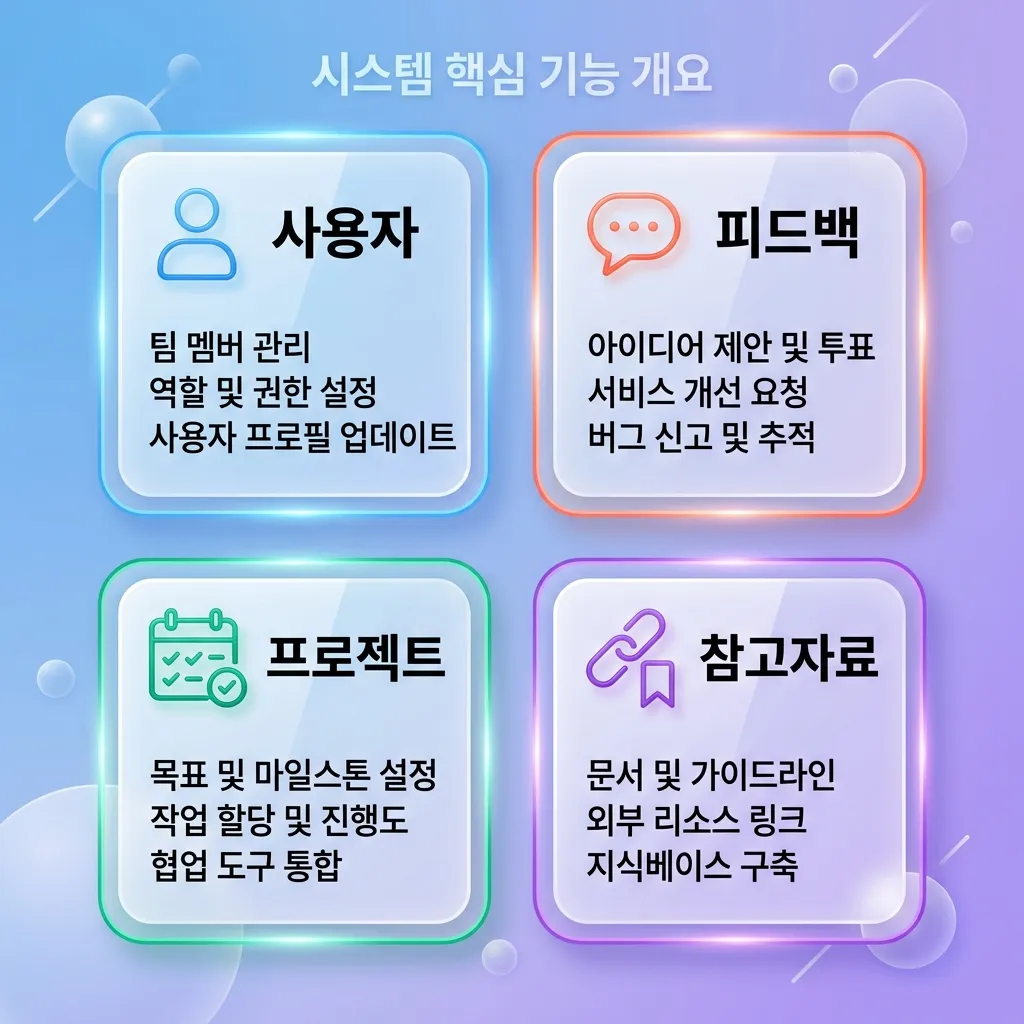
user — 사용자 정체성과 선호
“이 사람은 누구인가”를 적습니다. 역할, 전문성, 작업 스타일.
---
name: user_role
description: 사용자 역할·전문성·작업 환경
type: user
---
- 프로젝트 6개 동시 진행 (Astro 블로그 + Cloudflare Workers API + Next.js 포트폴리오 + B2B SaaS 대시보드 등)
- Astro · Cloudflare Pages 7년차, React 입문 단계
- macOS Sequoia + zsh, 외장 SSD에 작업 디렉터리 구성이렇게 한 줄 알아두면, 제가 React 관련 질문을 했을 때 Claude가 곧장 백엔드 비유로 설명을 시작합니다.
feedback — “이렇게 해라/하지 마라”의 이유까지
가장 중요한 카테고리입니다. 교정뿐 아니라 “잘했다”고 확인한 판단도 같이 저장해야 합니다. 그래야 Claude가 점점 보수적으로만 변하지 않거든요.
---
name: feedback_writing_style
description: 블로그 본문 어조와 금지 표현
type: feedback
---
본문은 존댓말로만 작성한다. "~다", "~한다" 반말 종결 금지.
**Why:** 독자 페르소나가 30~50대 한국어 사용자, 친근한 어조가 체류시간 22% 더 높았던 GA4 데이터 있음.
**How to apply:** 모든 블로그 글, 이메일 답장, 메모 파일 본문에 적용. 코드 주석은 예외.Why와 How to apply 두 줄을 같이 적는 게 핵심입니다. 이유를 알면 Claude가 엣지 케이스에서도 판단할 수 있습니다.
project — 진행 중 작업·결정·일정
상대 날짜는 절대 날짜로 변환해 저장합니다. “이번 주 목요일까지”는 한 달 뒤에 무용지물이지만, “2026-05-01까지”는 6개월 뒤에도 의미가 있습니다.
---
name: project_domain_migration
description: tech.dokyungja.us → dokyungja.us 통합 작업 진행 상황
type: project
---
2026-04-27 tech 서브도메인 콘텐츠를 메인 도메인 /tech 서브폴더로 통합 완료.
**Why:** SEO 권한 분산 방지 + GSC 단일 속성으로 통합해 분석 단순화.
**How to apply:** 1주일간 GSC 색인 변화 모니터링, 5월 4일에 후속 글 발행 예정.reference — 외부 시스템 위치만 짧게
코드 안에 없는 외부 자원의 위치를 적습니다. URL, 채널 이름, 대시보드 주소.
---
name: reference_naver_blog_api
description: 네이버 SE ONE API 발행 워크플로우 위치
type: reference
---
네이버 블로그 자동 발행은 BlogManagement/naver_rabbit/ 사용. 임시저장 명령 ./draft posts/foo.md.
설정 파일은 ~/.naver_rabbit/config.toml에 blog_id와 default_category 저장됨.두 단계로 저장하기 — 파일 + 인덱스
여기가 초보자가 가장 많이 놓치는 포인트입니다. 메모리는 두 곳에 동시에 적어야 작동합니다.
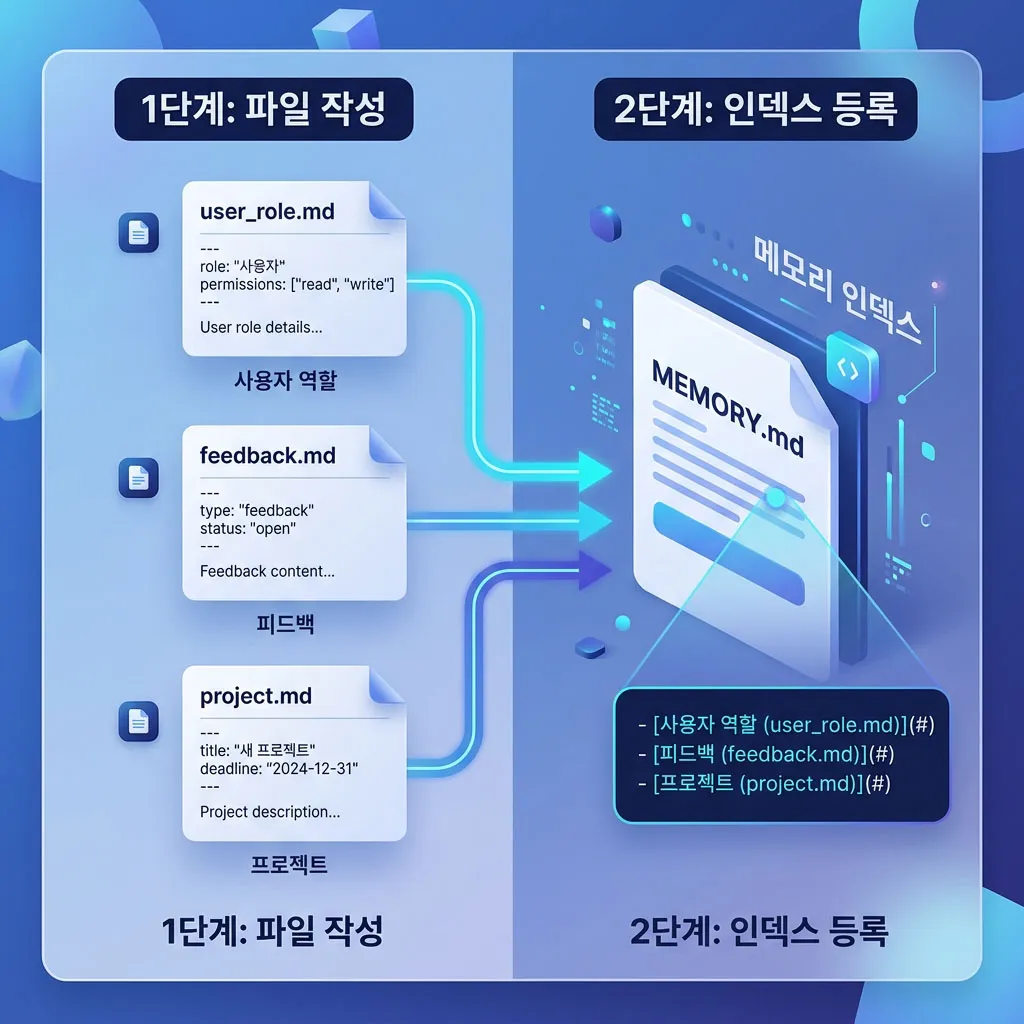
Step 1 — 개별 파일에 본문 작성
위에서 본 4가지 예시처럼, frontmatter(name, description, type) + 본문 구조로 한 토픽당 한 파일을 만듭니다. 파일명은 의미별로 짓습니다. “날짜순(2026-04.md)으로 묶지 마세요. 시간이 지나면 무엇이 들었는지 알 수 없게 됩니다.”
Step 2 — MEMORY.md에 한 줄 포인터만 추가
MEMORY.md는 인덱스입니다. 매 대화마다 자동 로드되지만, 200줄 이후는 잘립니다. 그래서 본문은 절대 여기 쓰면 안 됩니다.
- [user_role](user_role.md) — 프로젝트 6개 동시 진행, Astro 7년/React 입문
- [feedback_writing_style](feedback_writing_style.md) — 본문 존댓말 강제, 반말 금지
- [project_domain_migration](project_domain_migration.md) — tech→메인 통합 4/27 완료, 5/4 후속 발행
- [reference_naver_blog_api](reference_naver_blog_api.md) — 네이버 발행 BlogManagement/naver_rabbit한 줄 ~150자 이하, - 제목 — 한 줄 hook 형식이 표준 패턴입니다.
저장하면 안 되는 것·갱신·삭제 규칙
💡 핵심 원칙
”코드를 읽으면 알 수 있는 건 메모리에 저장하지 않는다.”
저장 금지 목록을 모르면 메모리가 빠르게 쓰레기통이 됩니다.
- 코드 패턴·아키텍처·파일 경로 — 직접 코드를 읽어서 확인할 수 있는 정보
- git 변경 이력·누가 수정했는지 —
git log·git blame이 정답 - 버그 수정 레시피 — 코드에 이미 반영되어 있고, 커밋 메시지에 맥락이 있음
- CLAUDE.md에 이미 적힌 규칙 — 중복은 둘 다 stale 위험
- 현재 진행 중인 작업 상태 — 그건 Plan/Task의 영역
시간 경과 검증이 또 하나의 규칙입니다. 메모리에 적힌 함수명·파일 경로·플래그는 “메모리를 쓴 시점에 존재했다”는 주장일 뿐입니다. 그 후 리네임됐을 수도, 삭제됐을 수도 있습니다. 사용자가 메모리 기반으로 행동하려는 순간(예: “이 함수 좀 수정해줘”) 사용 직전에 grep으로 한 번 확인하는 습관이 짝꿍이 되어야 합니다.
충돌이 생기면 무조건 현재 코드/관측값 우선입니다. 옛 메모리는 그 자리에서 갱신하거나 삭제해야 합니다.
CLAUDE.md / Plan / Task / Memory — 4가지 도구 역할 분담
여기까지 오면 헷갈리는 게 정상입니다. “이 정보는 어디에 적어야 해?”라는 질문이 반드시 옵니다.
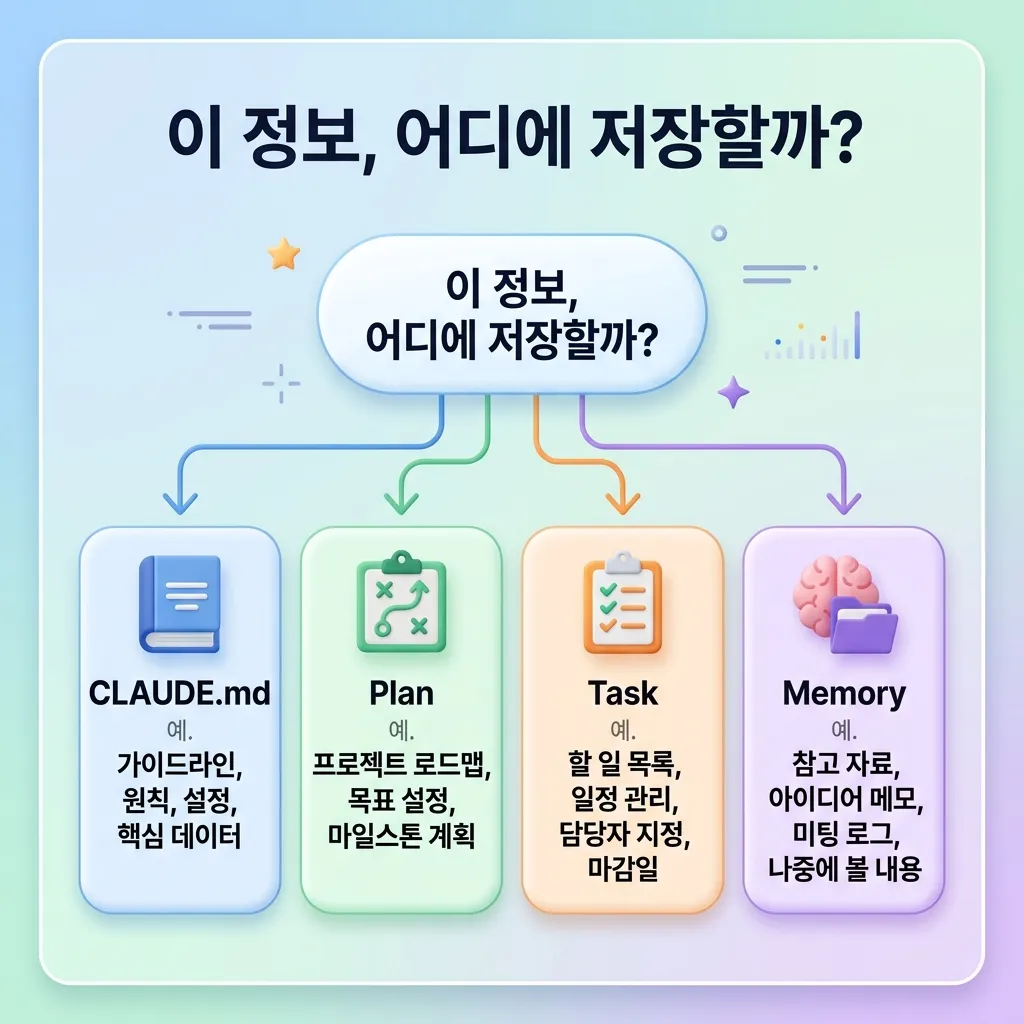
| 도구 | 역할 | 적용 범위 | 예시 |
|---|---|---|---|
| CLAUDE.md | 프로젝트 영구 규칙 | 모든 세션·모든 사용자 | ”pnpm 사용”, “테스트는 vitest”, “커밋 메시지 한국어” |
| Plan | 현재 작업 구현 전략 | 사용자 합의 후 구현 시작 | ”이 PR을 3개로 나눈다”, “마이그레이션은 staging부터” |
| Task | 현재 세션 진행 단계 | 시작 시 in_progress, 끝나면 completed | ”테스트 작성 → 실행 → 리뷰” |
| Memory | 다음 세션을 위한 지식 | 미래의 나에게 남기는 메모 | ”사용자는 Astro 7년차”, “지난번 _redirects로 깨짐” |
판단이 헷갈리는 3가지 경계 사례를 보면 감이 옵니다.
- “이 사용자는 Go 전문가야” → user memory (다음 세션에서도 유효, 사용자 정체성)
- “이번 PR을 3개로 나누자” → Plan (현재 작업 한정, 구현 전략)
- “한국어 주석 금지” → CLAUDE.md (모든 세션·모든 협업자에 적용)
실전 운영 팁: 프로젝트 6개 동시 굴리면서 배운 것
마지막으로 6개월간 운영하면서 효과 본 패턴 4가지만 공유합니다.
1. 첫 메모리는 user 한 줄로 시작. 가득 채울 필요 없습니다. “블로거이고 Astro+Cloudflare 사용” 한 줄만 있어도 다음 세션의 첫 응답이 바뀝니다.
2. feedback은 교정받은 그날 바로 적기. “이렇게 하지 마라”는 지적을 받으면, 그 자리에서 Claude에게 “이거 메모리에 저장해줘”라고 한마디 하면 됩니다. 다음번에 같은 지적을 두 번 하지 않게 됩니다.
3. project memory는 격주로 정리. 끝난 작업의 project 메모리는 빼서 따로 보관(예: archive/ 폴더)하거나 삭제합니다. 안 그러면 인덱스 200줄을 빠르게 채웁니다.
4. 새 환경에서는 메모리 폴더 동기화. 노트북·데스크탑·외장SSD를 옮겨다니면 메모리 폴더가 따라가야 효과가 있습니다. 저는 작업 디렉터리 자체를 외장 SSD에 두고, 메모리 폴더는 iCloud로 백업합니다. (단, 민감 정보가 들어가면 git private repo 또는 1Password로 옮기는 게 안전합니다.)
오늘 마이그레이션이 한 번에 끝난 것도, 위 4가지 패턴이 6개월간 누적된 결과였습니다. 메모리 시스템은 한 번 설정하면 끝이 아니라, 매일 한 줄씩 쌓이는 자산에 가깝습니다.
자주 묻는 질문 (FAQ)
Claude Code Memory와 ChatGPT Memory는 무엇이 다른가요?
두 시스템 모두 영속 지식을 저장한다는 목적은 같습니다. 차이는 Claude Code Memory가 파일 기반·완전 오픈·프로젝트별 격리라는 점입니다. ~/.claude/projects/<슬러그>/memory/ 안의 마크다운 파일을 직접 열어 편집할 수 있고, 프로젝트가 다르면 메모리도 분리됩니다. ChatGPT는 단일 사용자 단위로만 묶이고 직접 파일 편집은 불가합니다.
메모리 파일을 git에 커밋해도 되나요?
개인 메모리는 비추천입니다. user 메모리에는 작업 패턴·역량 등 사적인 정보가 들어가기 때문입니다. 팀 단위로 공유할 만한 규칙은 메모리가 아니라 CLAUDE.md에 적어 git에 올리는 게 맞는 곳입니다. 메모리 폴더 자체를 백업하고 싶으면 private repo나 클라우드 동기화(iCloud, Dropbox)를 쓰세요.
MEMORY.md가 200줄을 넘으면 어떻게 정리하나요?
우선순위: ① 끝난 project 메모리는 archive/ 폴더로 이동, ② 같은 토픽이 여러 줄에 분산됐다면 한 파일로 통합, ③ 한 줄 hook의 길이를 ~100자로 줄이기. 그래도 길면 디렉터리를 의미별로 나눠 인덱스를 다시 짭니다(예: memory/user/, memory/feedback/).
user 메모리와 feedback 메모리는 어떻게 구분하나요?
기준은 단순합니다. user는 “이 사람이 누구인가”(정체성·역량·환경), feedback은 “어떻게 일해야 하는가”(행동 지침)입니다. “Astro 7년차”는 user, “Astro 글에서는 항상 Lighthouse 수치 첨부”는 feedback입니다.
저장한 메모리가 더 이상 맞지 않으면 어떻게 처리하나요?
발견 즉시 갱신 또는 삭제합니다. 옛 메모리를 근거로 행동하지 않는 게 가장 중요한 원칙입니다. 사용자가 행동을 요청한 순간(예: “그 함수 수정해줘”) 메모리 → 코드 → grep 순서로 검증한 뒤 진행하세요. stale 메모리를 발견하면 같은 대화 안에서 바로 갱신하고 다음 응답에 반영합니다.
CLAUDE.md에 적은 규칙도 메모리에 저장해야 하나요?
중복하면 안 됩니다. CLAUDE.md가 우선이고, 메모리에는 거기 없는 사실만 적습니다. 두 곳에 동시 저장하면 한쪽이 갱신되어도 다른 쪽이 stale로 남아 충돌의 원인이 됩니다.
Plan · Task · Memory 중 무엇을 먼저 써야 하나요?
시점 기준으로 나누면 답이 나옵니다. 현재 진행은 Task(세션 끝나면 완료/소멸), 구현 전략 합의는 Plan(작업 끝까지 유지), 다음 세션에 도움 될 지식은 Memory(영속). 작업 중에 “이 정보는 다음번에도 쓰일 것 같다”는 신호가 오면 그때 Memory로 옮기면 됩니다.
관련 글
- Claude Code Hooks로 Git Commit 자동화하기 — AI가 코딩 끝내면 알림까지
- Claude Code .claudignore 설정으로 Pro·Max 사용 한도 체감 2배 늘리기
- Claude Code 실전 가이드 — 터미널에서 AI와 페어 프로그래밍하는 법
📩 경자씨 경제 소식 받기
기준금리·세금·정부지원금 핵심만 골라 이메일로 보내드려요.
구독 시 이메일 수집·발송에 동의하는 것으로 간주됩니다. 언제든 해지할 수 있으며, 자세한 내용은 개인정보처리방침을 참고하세요.